家里面闲置一台手机,手机的像素还算不错,于是就想利用手机的摄像功能代替摄像头,来收集拍摄些图片进行深度学习。
这个手机被我用钉子固定在一块木板上了
捣鼓这个东西太费时间太费力了,因为一个人的工作,我一边调动作一边拍照,弄了一下午胳膊也麻了。
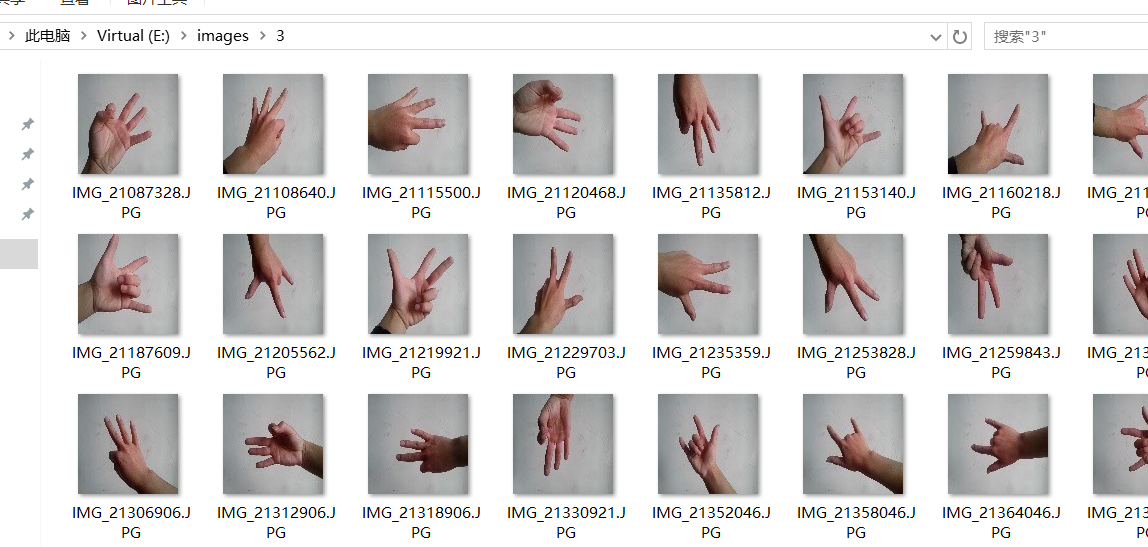
最后0-5个数字分别拍了60张,成果如下(之前没有截图,现在剩下我处理过的了都是100*100的照片了):
拍完后的照片都是640*480格式大小的,最后用opencv简单的resize成100 * 100的了
1 2 3 4 // 先用代码读取改路径下的所有照片名称 图片 = cv::imread(路径) cv::resize(图片,保存的图像,cv::Size(100,100)) cv::imwrite(路径, 保存的图像)
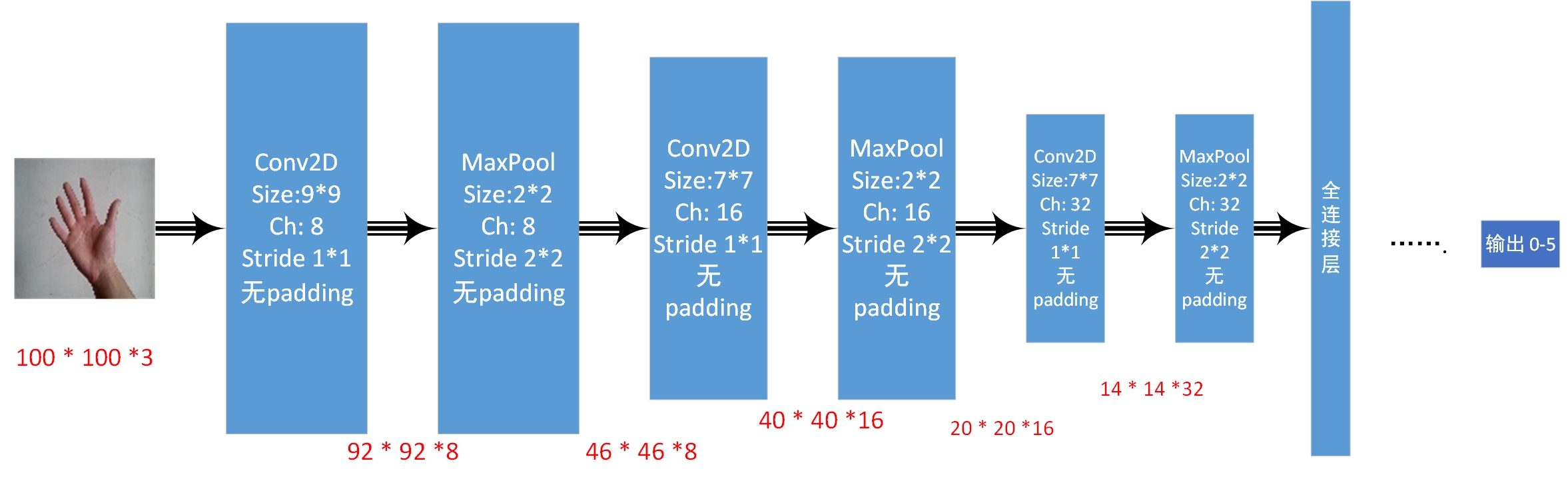
此模型采用的是自己瞎想的卷积神经网络,用了VGG的思想,但是最后结果不尽心意,抽时间改善模型
结果只有35%的成效,看来是模型很不行(笑哭),下次用用VGG-16试试水
1 2 3 4 import tensorflow as tfimport numpy as npimport tf_utilsimport MyData
1 X_train,y_train = MyData.load_datas()
(360, 1)
1 2 3 def weight (shape, stddev, name) : inital = tf.truncated_normal(shape, stddev=stddev) return tf.Variable(inital, name=name)
1 2 3 def bais (length, value, name) : inital = tf.constant(value, shape=length) return tf.Variable(inital, name=name)
1 2 3 def convert_to_one_hot (Y, C) : Y = np.eye(C)[Y.reshape(-1 )] return Y
1 2 def conv2d (x, W, stride, pad) : return tf.nn.conv2d(x, W, strides=stride, padding=pad)
1 2 def max_pool_2d (x, ksize, stride) : return tf.nn.max_pool(x, ksize=ksize, strides= stride, padding='SAME' )
1 m, height, width, channels = X_train.shape
1 2 X = tf.placeholder(tf.float32, [None , height, width, channels], name='X' ) y_true = tf.placeholder(tf.float32, [None , 6 ], name='y_true' )
1 2 3 4 5 6 7 8 conv_W_b = { 'W1' :weight([9 , 9 , channels, 10 ], 0.5 , 'W1' ), 'b1' :bais([10 ], 0.5 , 'b1' ), 'W2' :weight([7 , 7 , 10 , 16 ], 0.5 , 'W2' ), 'b2' :bais([16 ], 0.5 , 'b2' ), 'W3' :weight([7 , 7 , 16 , 32 ], 0.5 , 'W3' ), 'b3' :bais([32 ], 0.5 , 'b3' ), }
1 2 h_conv1 = tf.nn.relu(conv2d(X, conv_W_b['W1' ], [1 ,1 ,1 ,1 ], 'VALID' ) + conv_W_b['b1' ]) h_pool1 = max_pool_2d(h_conv1, [1 ,2 ,2 ,1 ], [1 ,2 ,2 ,1 ])
1 2 h_conv2 = tf.nn.relu(conv2d(h_pool1, conv_W_b['W2' ], [1 ,1 ,1 ,1 ], 'VALID' ) + conv_W_b['b2' ]) h_pool2 = max_pool_2d(h_conv2, [1 ,2 ,2 ,1 ], [1 ,2 ,2 ,1 ])
1 2 h_conv3 = tf.nn.relu(conv2d(h_pool2, conv_W_b['W3' ], [1 ,1 ,1 ,1 ], 'VALID' ) + conv_W_b['b3' ]) h_pool3 = max_pool_2d(h_conv3, [1 ,2 ,2 ,1 ], [1 ,2 ,2 ,1 ])
1 2 3 4 5 6 7 8 9 10 fc_W_b = { 'W_fc1' :weight([7 *7 *32 , 512 ], 0.5 , 'W_fc1' ), 'b_fc1' :bais([512 ], 0.1 , 'b_fc1' ), 'W_fc2' :weight([512 , 512 ], 0.5 , 'W_fc2' ), 'b_fc2' :bais([512 ], 0.1 , 'b_fc2' ), 'W_fc3' :weight([512 ,64 ], 0.5 , 'W_fc3' ), 'b_fc3' :bais([64 ], 0.1 , 'b_fc3' ), 'W_out' :weight([64 , 6 ], 0.5 , 'W_out' ), 'b_out' :bais([6 ], 0.1 , 'b_out' ) }
1 2 h_flat = tf.reshape(h_pool3, [-1 , 7 *7 *32 ]) h_fc1 = tf.nn.relu(tf.matmul(h_flat, fc_W_b['W_fc1' ]) + fc_W_b['b_fc1' ])
1 2 keep_prob = tf.placeholder(tf.float32) h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
1 2 h_fc2 = tf.nn.relu(tf.matmul(h_fc1_drop, fc_W_b['W_fc2' ]) + fc_W_b['b_fc2' ]) h_fc2_drop = tf.nn.dropout(h_fc2, keep_prob)
1 2 h_fc3 = tf.nn.relu(tf.matmul(h_fc2_drop, fc_W_b['W_fc3' ]) + fc_W_b['b_fc3' ]) h_fc3_drop = tf.nn.dropout(h_fc3, keep_prob)
1 y_out = tf.nn.softmax(tf.matmul(h_fc3_drop, fc_W_b['W_out' ]) + fc_W_b['b_out' ], name='output' )
1 2 3 4 5 6 7 8 9 def next_batch (train_data, train_target, batch_size) : index = [ i for i in range(0 ,len(train_target)) ] np.random.shuffle(index); batch_data = []; batch_target = []; for i in range(0 ,batch_size): batch_data.append(train_data[index[i]]); batch_target.append(train_target[index[i]]) return batch_data, batch_target
1 2 3 4 5 cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=y_out, labels=y_true) cost = tf.reduce_mean(cross_entropy) optimizer = tf.train.AdamOptimizer(0.0008 ).minimize(cost) correct_prediction = tf.equal(tf.argmax(y_out, 1 ), tf.argmax(y_true, 1 )) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
1 2 3 4 y_train = convert_to_one_hot(y_train, 6 ) X_train = X_train / 255
1 2 3 4 5 6 7 8 9 10 11 12 with tf.Session() as sess: sess.run(tf.global_variables_initializer()) for i in range(2000 ): batch_x, batch_y = next_batch(X_train, y_train, 16 ) np.random.seed(i) _, c = sess.run([optimizer, cost], feed_dict={X:batch_x, y_true:batch_y, keep_prob:0.5 }) if (i%100 == 0 or i==1999 ) and i!=0 : acc = sess.run(accuracy,feed_dict={X:batch_x, y_true:batch_y, keep_prob:1.0 }) print('迭代%d 正确率为%f' %(i+1 , acc))
迭代101 正确率为0.187500
迭代201 正确率为0.375000
迭代301 正确率为0.187500
迭代401 正确率为0.125000
迭代501 正确率为0.125000
迭代601 正确率为0.312500
迭代701 正确率为0.312500
迭代801 正确率为0.125000
迭代901 正确率为0.062500
迭代1001 正确率为0.187500
迭代1101 正确率为0.125000
迭代1201 正确率为0.125000
迭代1301 正确率为0.000000
迭代1401 正确率为0.125000
迭代1501 正确率为0.312500
迭代1601 正确率为0.125000
迭代1701 正确率为0.250000
迭代1801 正确率为0.250000
迭代1901 正确率为0.125000
迭代2000 正确率为0.187500